Mon 28 AprDisplayed time zone: Eastern Time (US & Canada) change
07:00 - 19:00 | Ready Room MondayICSE Social, Networking and Special Rooms at 209 The Ready Room will be available throughout the week. There will be some tables with computers where people can edit presentations (bring on a USB stick) and upload presentations to the presentation rooms through the Contact 1 website. There will also be AV technicians to help if needed. You do not need to use the Ready Room: You have several choices: You can upload your presentation from your own computer in advance of your session (days in advance even) at the Contact 1 website (you will be sent a link). Or you can plug your computer in using an HDMI cable when you are starting your presentation. This last option is available but not recommended, since it increases the chance of delays. There will be some tables and couches in the Ready Room where you can get work done, or have small get-togethers with people. This room will not be ‘quiet’. If you want a quiet place to work or chill out (library quiet, no talking) then Room 209 will be available much of the time. The Ready Room will also have some poster boards. | ||
07:00 - 19:00 | Ready Room MondayICSE Social, Networking and Special Rooms at 209 The Ready Room will be available throughout the week. There will be some tables with computers where people can edit presentations (bring on a USB stick) and upload presentations to the presentation rooms through the Contact 1 website. There will also be AV technicians to help if needed. You do not need to use the Ready Room: You have several choices: You can upload your presentation from your own computer in advance of your session (days in advance even) at the Contact 1 website (you will be sent a link). Or you can plug your computer in using an HDMI cable when you are starting your presentation. This last option is available but not recommended, since it increases the chance of delays. There will be some tables and couches in the Ready Room where you can get work done, or have small get-togethers with people. This room will not be ‘quiet’. If you want a quiet place to work or chill out (library quiet, no talking) then Room 209 will be available much of the time. The Ready Room will also have some poster boards. | ||
09:00 - 10:30 | |||
09:00 - 10:30 | |||
09:00 - 10:30 | Plenary: Opening + Joint MSR + ICPC KeynoteProgram / Keynotes at 214 Chair(s): Bram Adams Queen's University, Olga Baysal Carleton University, Michael W. Godfrey University of Waterloo, Canada, Ayushi Rastogi University of Groningen, The Netherlands | ||
09:00 30mDay opening | Official Opening Program | ||
09:30 60mKeynote | Mining BOMs for Improving Supply Chain Efficiency & Resilience Keynotes Kate Stewart Linux Foundation File Attached | ||
10:30 - 11:00 | |||
10:30 30mBreak | Monday Morning Break ICSE Catering | ||
10:30 - 11:00 | |||
10:30 30mBreak | Monday Morning Break ICSE Catering | ||
11:00 - 12:30 | |||
11:00 - 12:30 | |||
11:00 - 12:30 | Defects, bugs, and issuesData and Tool Showcase Track / Technical Papers / Registered Reports / Program at 214 Chair(s): Minhaz Zibran Idaho State University | ||
11:00 10mTalk | Learning from Mistakes: Understanding Ad-hoc Logs through Analyzing Accidental Commits Technical Papers Yi-Hung Chou University of California, Irvine, Yiyang Min Amazon, April Wang ETH Zürich, James Jones University of California at Irvine Pre-print | ||
11:10 10mTalk | On the calibration of Just-in-time Defect Prediction Technical Papers Xhulja Shahini paluno - University of Duisburg-Essen, Jone Bartel University of Duisburg-Essen, paluno, Klaus Pohl University of Duisburg-Essen, paluno | ||
11:20 10mTalk | An Empirical Study on Leveraging Images in Automated Bug Report Reproduction Technical Papers Dingbang Wang University of Connecticut, Zhaoxu Zhang University of Southern California, Sidong Feng Monash University, William G.J. Halfond University of Southern California, Tingting Yu University of Connecticut | ||
11:30 10mTalk | It’s About Time: An Empirical Study of Date and Time Bugs in Open-Source Python SoftwareTechnical Track Distinguished Paper Award Technical Papers Shrey Tiwari Carnegie Mellon University, Serena Chen University of California, San Diego, Alexander Joukov Stony Brook University, Peter Vandervelde University of California, Santa Barbara, Ao Li Carnegie Mellon University, Rohan Padhye Carnegie Mellon University Pre-print | ||
11:40 10mTalk | Enhancing Just-In-Time Defect Prediction Models with Developer-Centric Features Technical Papers Emanuela Guglielmi University of Molise, Andrea D'Aguanno University of Molise, Rocco Oliveto University of Molise, Simone Scalabrino University of Molise | ||
11:50 10mTalk | Revisiting Defects4J for Fault Localization in Diverse Development Scenarios Technical Papers Md Nakhla Rafi Concordia University, An Ran Chen University of Alberta, Tse-Hsun (Peter) Chen Concordia University, Shaohua Wang Central University of Finance and Economics | ||
12:00 5mTalk | Mining Bug Repositories for Multi-Fault Programs Data and Tool Showcase Track | ||
12:05 5mTalk | HaPy-Bug - Human Annotated Python Bug Resolution Dataset Data and Tool Showcase Track Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Radosław Woźniak Nicolaus Copernicus University in Toruń, Łukasz Halada University of Wrocław, Poland, Aleksander Kazecki Nicolaus Copernicus University in Toruń, Mykhailo Molchanov Igor Sikorsky Kyiv Polytechnic Institute, Ukraine, Krzysztof Stencel University of Warsaw Pre-print File Attached | ||
12:10 5mTalk | SPRINT: An Assistant for Issue Report Management Data and Tool Showcase Track Pre-print | ||
12:15 5mTalk | Identifying and Replicating Code Patterns Driving Performance Regressions in Software Systems Registered Reports Denivan Campos University of Molise, Luana Martins University of Salerno, Emanuela Guglielmi University of Molise, Michele Tucci University of L'Aquila, Daniele Di Pompeo University of L'Aquila, Simone Scalabrino University of Molise, Vittorio Cortellessa University of L'Aquila, Dario Di Nucci University of Salerno, Rocco Oliveto University of Molise | ||
12:30 - 14:00 | |||
12:30 90mLunch | Monday Lunch ICSE Catering | ||
12:30 - 14:00 | |||
12:30 90mLunch | Monday Lunch ICSE Catering | ||
12:30 - 14:00 | |||
12:30 90mLunch | MSR Diversity Lunch Catering | ||
12:30 - 14:00 | |||
12:30 90mLunch | MSR Diversity Lunch Catering | ||
13:00 - 14:00 | MSR Poster (Monday)Data and Tool Showcase Track / Technical Papers / Mining Challenge / Program at Canada Hall 3 Poster Area | ||
13:00 60mTalk | SPRINT: An Assistant for Issue Report Management Data and Tool Showcase Track Pre-print | ||
13:00 60mTalk | Combining Large Language Models with Static Analyzers for Code Review Generation Technical Papers Imen Jaoua DIRO, Université de Montréal, Oussama Ben Sghaier DIRO, Université de Montréal, Houari Sahraoui DIRO, Université de Montréal Pre-print | ||
13:00 60mTalk | Can LLMs Replace Manual Annotation of Software Engineering Artifacts?Technical Track Distinguished Paper Award Technical Papers Toufique Ahmed IBM Research, Prem Devanbu University of California at Davis, Christoph Treude Singapore Management University, Michael Pradel University of Stuttgart Pre-print | ||
13:00 60mTalk | Dependency Update Adoption Patterns in the Maven Software Ecosystem Mining Challenge Baltasar Berretta College of Wooster, Augustus Thomas College of Wooster, Heather Guarnera The College of Wooster | ||
13:00 60mTalk | Popularity and Innovation in Maven Central Mining Challenge Nkiru Ede Victoria University of Wellington, Jens Dietrich Victoria University of Wellington, Ulrich Zülicke Victoria University of Wellington Pre-print | ||
13:00 60mTalk | Chasing the Clock: How Fast Are Vulnerabilities Fixed in the Maven Ecosystem? Mining Challenge Md Fazle Rabbi Idaho State University, Arifa Islam Champa Idaho State University, Rajshakhar Paul Wayne State University, Minhaz F. Zibran Idaho State University Pre-print | ||
13:00 60mTalk | SCRUBD: Smart Contracts Reentrancy and Unhandled Exceptions Vulnerability Dataset Data and Tool Showcase Track Chavhan Sujeet Yashavant Indian Institute of Technology, Kanpur, Mitrajsinh Chavda Indian Institute of Technology Kanpur, India, Saurabh Kumar Indian Institute of Technology Hyderabad, India, Amey Karkare IIT Kanpur, Angshuman Karmakar Indian Institute of Technology Kanpur, India Pre-print | ||
13:00 60mTalk | TerraDS: A Dataset for Terraform HCL Programs Data and Tool Showcase Track Christoph Buehler University of St. Gallen, David Spielmann University of St. Gallen, Roland Meier armasuisse, Guido Salvaneschi University of St. Gallen Pre-print | ||
13:00 60mTalk | Mining a Decade of Contributor Dynamics in Ethereum: A Longitudinal StudyFOSS Award Technical Papers Matteo Vaccargiu University of Cagliari, Sabrina Aufiero University College London (UCL), Cheick Ba Queen Mary University of London, Silvia Bartolucci University College London, Richard Clegg Queen Mary University London, Daniel Graziotin University of Hohenheim, Rumyana Neykova Brunel University London, Roberto Tonelli University of Cagliari, Giuseppe Destefanis Brunel University of London Pre-print | ||
13:00 60mTalk | CoMRAT: Commit Message Rationale Analysis Tool Data and Tool Showcase Track Mouna Dhaouadi University of Montreal, Bentley Oakes Polytechnique Montréal, Michalis Famelis Université de Montréal Pre-print Media Attached File Attached | ||
13:00 60mTalk | A Dataset of Software Bill of Materials for Evaluating SBOM Consumption Tools Data and Tool Showcase Track Rio Kishimoto Osaka University, Tetsuya Kanda Notre Dame Seishin University, Yuki Manabe The University of Fukuchiyama, Katsuro Inoue Nanzan University, Shi Qiu Toshiba, Yoshiki Higo Osaka University Pre-print | ||
13:00 60mTalk | A Dataset of Contributor Activities in the NumFocus Open-Source CommunityData/Tool Track Distinguished Dataset Award Data and Tool Showcase Track Youness Hourri University of Mons, Alexandre Decan University of Mons; F.R.S.-FNRS, Tom Mens University of Mons Pre-print | ||
13:00 60mTalk | Does Functional Package Management Enable Reproducible Builds at Scale? Yes.Technical Track Distinguished Paper Award Technical Papers Julien Malka LTCI, Télécom Paris, Institut Polytechnique de Paris, France, Stefano Zacchiroli LTCI, Télécom Paris, Institut Polytechnique de Paris, Palaiseau, France, Théo Zimmermann Télécom Paris, Polytechnic Institute of Paris Pre-print | ||
13:00 60mTalk | HaPy-Bug - Human Annotated Python Bug Resolution Dataset Data and Tool Showcase Track Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Radosław Woźniak Nicolaus Copernicus University in Toruń, Łukasz Halada University of Wrocław, Poland, Aleksander Kazecki Nicolaus Copernicus University in Toruń, Mykhailo Molchanov Igor Sikorsky Kyiv Polytechnic Institute, Ukraine, Krzysztof Stencel University of Warsaw Pre-print File Attached | ||
13:00 60mTalk | Do LLMs Provide Links to Code Similar to what they Generate? A Study with Gemini and Bing CoPilot Technical Papers Daniele Bifolco University of Sannio, Pietro Cassieri University of Salerno, Giuseppe Scanniello University of Salerno, Massimiliano Di Penta University of Sannio, Italy, Fiorella Zampetti University of Sannio, Italy Pre-print | ||
13:00 60mTalk | Out of Sight, Still at Risk: The Lifecycle of Transitive Vulnerabilities in Maven Mining Challenge Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Krzysztof Rykaczewski Nicolaus Copernicus University in Toruń, Poland, Krzysztof Stencel University of Warsaw Pre-print | ||
13:00 60mTalk | Refactoring for Dockerfile Quality: A Dive into Developer Practices and Automation Potential Technical Papers Emna Ksontini University of Michigan, Meriem Mastouri University of Michigan, Rania Khalsi University of Michigan - Flint, Wael Kessentini DePaul University | ||
13:00 60mTalk | Cascading Effects: Analyzing Project Failure Impact in the Maven Central Ecosystem Mining Challenge Mina Shehata Belmont University, Saidmakhmud Makhkamjonoov Belmont University, Mahad Syed Belmont University, Esteban Parra Rodriguez Belmont University | ||
13:00 60mTalk | MaLAware: Automating the Comprehension of Malicious Software Behaviours using Large Language Models (LLMs) Data and Tool Showcase Track BIKASH SAHA Indian Institute of Technology Kanpur, Nanda Rani Indian Institute of Technology Kanpur, Sandeep K. Shukla Indian Institute of Technology Kanpur Pre-print | ||
13:00 60mTalk | Investigating the Understandability of Review Comments on Code Change Requests Technical Papers Md Shamimur Rahman University of Saskatchewan, Zadia Codabux University of Saskatchewan, Chanchal K. Roy University of Saskatchewan | ||
14:00 - 15:30 | |||
14:00 - 15:30 | |||
14:00 - 15:30 | MSR 2025 Mining ChallengeMining Challenge / Program at 215 Chair(s): Joyce El Haddad Université Paris Dauphine - PSL , Damien Jaime Université Paris Nanterre & LIP6, Pascal Poizat Université Paris Nanterre & LIP6 | ||
14:00 4mTalk | Analyzing Dependency Clusters and Security Risks in the Maven Central Repository Mining Challenge | ||
14:04 4mTalk | Chasing the Clock: How Fast Are Vulnerabilities Fixed in the Maven Ecosystem? Mining Challenge Md Fazle Rabbi Idaho State University, Arifa Islam Champa Idaho State University, Rajshakhar Paul Wayne State University, Minhaz F. Zibran Idaho State University Pre-print | ||
14:08 4mTalk | Decoding Dependency Risks: A Quantitative Study of Vulnerabilities in the Maven Ecosystem Mining Challenge Costain Nachuma Idaho State University, Md Mosharaf Hossan Idaho State University, Asif Kamal Turzo Wayne State University, Minhaz F. Zibran Idaho State University Pre-print | ||
14:12 4mTalk | Faster Releases, Fewer Risks: A Study on Maven Artifact Vulnerabilities and Lifecycle ManagementChallenge Track Best Mining Challenge Paper Mining Challenge Md Shafiullah Shafin Rajshahi University of Engineering & Technology (RUET), Md Fazle Rabbi Idaho State University, S. M. Mahedy Hasan Rajshahi University of Engineering & Technology, Minhaz F. Zibran Idaho State University Pre-print | ||
14:16 4mTalk | Insights into Dependency Maintenance Trends in the Maven Ecosystem Mining Challenge Barisha Chowdhury Rajshahi University of Engineering & Technology, Md Fazle Rabbi Idaho State University, S. M. Mahedy Hasan Rajshahi University of Engineering & Technology, Minhaz F. Zibran Idaho State University Pre-print | ||
14:20 4mTalk | Insights into Vulnerability Trends in Maven Artifacts: Recurrence, Popularity, and User Behavior Mining Challenge Courtney Bodily Idaho State University, Eric Hill Idaho State University, Andreas Kramer Idaho State University, Leslie Kerby Idaho State University, Minhaz F. Zibran Idaho State University | ||
14:24 4mTalk | Understanding Software Vulnerabilities in the Maven Ecosystem: Patterns, Timelines, and Risks Mining Challenge Md Fazle Rabbi Idaho State University, Rajshakhar Paul Wayne State University, Arifa Islam Champa Idaho State University, Minhaz F. Zibran Idaho State University Pre-print | ||
14:28 4mTalk | Dependency Update Adoption Patterns in the Maven Software Ecosystem Mining Challenge Baltasar Berretta College of Wooster, Augustus Thomas College of Wooster, Heather Guarnera The College of Wooster | ||
14:32 4mTalk | Analyzing Vulnerability Overestimation in Software Projects Mining Challenge Taha Draoui University of Michigan-Flint, Faten Jebari University of Michigan-Flint, Chawki Ben Slimen University of Michigan-Flint, Munjaap Uppal University of Michigan-Flint, Mohamed Wiem Mkaouer University of Michigan - Flint | ||
14:36 4mTalk | Dependency Dilemmas: A Comparative Study of Independent and Dependent Artifacts in Maven Ecosystem Mining Challenge Mehedi Hasan Shanto University of Windsor, Muhammad Asaduzzaman University of Windsor, Manishankar Mondal Khulna University, Shaiful Chowdhury University of Manitoba Pre-print | ||
14:40 4mTalk | Cascading Effects: Analyzing Project Failure Impact in the Maven Central Ecosystem Mining Challenge Mina Shehata Belmont University, Saidmakhmud Makhkamjonoov Belmont University, Mahad Syed Belmont University, Esteban Parra Rodriguez Belmont University | ||
14:45 4mTalk | Do Developers Depend on Deprecated Library Versions? A Mining Study of Log4j Mining Challenge Haruhiko Yoshioka Nara Institute of Science and Technology, Sila Lertbanjongngam Nara Institute of Science and Technology, Masayuki Inaba Nara Institute of Science and Technology, Youmei Fan Nara Institute of Science and Technology, Takashi Nakano Nara Institute of Science and Technology, Kazumasa Shimari Nara Institute of Science and Technology, Raula Gaikovina Kula The University of Osaka, Kenichi Matsumoto Nara Institute of Science and Technology Pre-print | ||
14:49 4mTalk | Mining for Lags in Updating Critical Security Threats: A Case Study of Log4j Library Mining Challenge Hidetake Tanaka Nara Institute of Science and Technology, Kazuma Yamasaki Nara Institute of Science and Technology, Momoka Hirose Nara Institute of Science and Technology, Takashi Nakano Nara Institute of Science and Technology, Youmei Fan Nara Institute of Science and Technology, Kazumasa Shimari Nara Institute of Science and Technology, Raula Gaikovina Kula The University of Osaka, Kenichi Matsumoto Nara Institute of Science and Technology Pre-print | ||
14:53 4mTalk | On the Evolution of Unused Dependencies in Java Project Releases: An Empirical Study Mining Challenge Nabhan Suwanachote Nara Institute of Science and Technology, Yagut Shakizada Nara Institute of Science and Technology, Yutaro Kashiwa Nara Institute of Science and Technology, Bin Lin Hangzhou Dianzi University, Hajimu Iida Nara Institute of Science and Technology | ||
14:57 4mTalk | Out of Sight, Still at Risk: The Lifecycle of Transitive Vulnerabilities in Maven Mining Challenge Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Krzysztof Rykaczewski Nicolaus Copernicus University in Toruń, Poland, Krzysztof Stencel University of Warsaw Pre-print | ||
15:01 4mTalk | Popularity and Innovation in Maven Central Mining Challenge Nkiru Ede Victoria University of Wellington, Jens Dietrich Victoria University of Wellington, Ulrich Zülicke Victoria University of Wellington Pre-print | ||
15:05 4mTalk | Software Bills of Materials in Maven Central Mining Challenge Yogya Gamage Universtité de Montréal, Nadia Gonzalez Fernandez Université de Montréal, Martin Monperrus KTH Royal Institute of Technology, Benoit Baudry Université de Montréal | ||
15:09 4mTalk | The Ripple Effect of Vulnerabilities in Maven Central: Prevalence, Propagation, and Mitigation Challenges Mining Challenge | ||
15:13 4mTalk | Tracing Vulnerabilities in Maven: A Study of CVE lifecycles and Dependency Networks Mining Challenge Pre-print | ||
15:17 4mTalk | Understanding Abandonment and Slowdown Dynamics in the Maven EcosystemChallenge Track Best Student Presentation Award Mining Challenge Kazi Amit Hasan Queen's University, Canada, Jerin Yasmin Queen's University, Canada, Huizi Hao Queen's University, Canada, Yuan Tian Queen's University, Kingston, Ontario, Safwat Hassan University of Toronto, Steven Ding Pre-print | ||
15:21 4mTalk | Characterizing Packages for Vulnerability Prediction Mining Challenge Saviour Owolabi University of Calgary, Francesco Rosati University of Calgary, Ahmad Abdellatif University of Calgary, Lorenzo De Carli University of Calgary, Canada | ||
15:25 4mTalk | Understanding the Popularity of Packages in Maven Ecosystem Mining Challenge Sadman Jashim Sakib University of Windsor, Muhammad Asaduzzaman University of Windsor, Curtis Bright University of Windsor, Cole Morgan University of Windsor Pre-print | ||
15:30 - 16:00 | |||
15:30 30mBreak | Monday Afternoon Break ICSE Catering | ||
15:30 - 16:00 | |||
15:30 30mBreak | Monday Afternoon Break ICSE Catering | ||
16:00 - 17:30 | |||
16:00 - 17:30 | |||
17:30 - 22:00 | |||
18:00 4hDinner | Dinner Catering | ||
17:30 - 22:00 | |||
18:00 4hDinner | Dinner Catering | ||
Tue 29 AprDisplayed time zone: Eastern Time (US & Canada) change
07:00 - 19:00 | |||
09:00 - 10:30 | Plenary: MIP + FCAMIP Award / FOSS Award / Vision and Reflection / Program at 214 Chair(s): Gabriele Bavota Software Institute @ Università della Svizzera Italiana, Jin L.C. Guo McGill University, Audris Mockus The University of Tennessee, Knoxville / Vilnius University, Martin Pinzger Universität Klagenfurt, Romain Robbes CNRS, LaBRI, University of Bordeaux, Patanamon Thongtanunam The University of Melbourne | ||
09:00 30mAwards | MSR 2025 Most Influential Paper Award: Toward deep learning software repositoriesMost Influential Paper Award MIP Award Martin White Syneos Health, Christopher Vendome Miami University, Mario Linares-Vásquez Universidad de los Andes, Denys Poshyvanyk William & Mary | ||
09:30 30mAwards | Myriad People Open Source Software for New Media ArtsFOSS Award (Runner-up) FOSS Award Benoit Baudry Université de Montréal, Erik Natanael Gustafsson Independent artist, Roni Kaufman Independent artist, Maria Kling Independent artist Pre-print | ||
10:00 30mTalk | The Standard of Rigor for MSR Research: A 20-Year Evolution Vision and Reflection Bogdan Vasilescu Raj Reddy Associate Professor of Software and Societal Systems, Carnegie Mellon University, USA Pre-print | ||
10:30 - 11:00 | |||
10:30 30mBreak | Tuesday Morning Break ICSE Catering | ||
11:00 - 12:30 | Build systems and DevOpsData and Tool Showcase Track / Technical Papers / Tutorials / Program at 215 Chair(s): Massimiliano Di Penta University of Sannio, Italy | ||
11:00 10mTalk | Build Scripts Need Maintenance Too: A Study on Refactoring and Technical Debt in Build Systems Technical Papers Anwar Ghammam Oakland University, Dhia Elhaq Rzig University of Michigan - Dearborn, Mohamed Almukhtar Oakland University, Rania Khalsi University of Michigan - Flint, Foyzul Hassan University of Michigan at Dearborn, Marouane Kessentini Grand Valley State University | ||
11:10 10mTalk | LLMSecConfig: An LLM-Based Approach for Fixing Software Container Misconfigurations Technical Papers Ziyang Ye The University of Adelaide, Triet Le The University of Adelaide, Muhammad Ali Babar School of Computer Science, The University of Adelaide Pre-print | ||
11:20 10mTalk | How Do Infrastructure-as-Code Practitioners Update Their Dependencies? An Empirical Study on Terraform Module Updates Technical Papers Mahi Begoug , Ali Ouni ETS Montreal, University of Quebec, Moataz Chouchen Department of Electrical and Computer Engineering, Concordia University, Montreal, Canada | ||
11:30 5mTalk | TerraDS: A Dataset for Terraform HCL Programs Data and Tool Showcase Track Christoph Buehler University of St. Gallen, David Spielmann University of St. Gallen, Roland Meier armasuisse, Guido Salvaneschi University of St. Gallen Pre-print | ||
11:35 5mTalk | CARDS: A collection of package, revision, and miscelleneous dependency graphs Data and Tool Showcase Track Euxane TRAN-GIRARD LIGM, CNRS, Université Gustave Eiffel, Laurent BULTEAU LIGM, CNRS, Université Gustave Eiffel, Pierre-Yves DAVID Octobus S.c.o.p. Pre-print | ||
11:40 5mTalk | GHALogs: Large-scale dataset of GitHub Actions runs Data and Tool Showcase Track Florent Moriconi EURECOM, AMADEUS, Thomas Durieux TU Delft, Jean-Rémy Falleri Univ. Bordeaux, CNRS, Bordeaux INP, LaBRI, UMR 5800, Institut Universitaire de France, Raphaël Troncy EURECOM, Aurélien Francillon EURECOM | ||
11:45 5mTalk | OSPtrack: A Labeled Dataset Targeting Simulated Execution of Open-Source Software Data and Tool Showcase Track Zhuoran Tan University of Glasgow, Christos Anagnostopoulos University of Glasgow, Jeremy Singer University of Glasgow | ||
11:50 40mTutorial | Agents for Software Development Tutorials Graham Neubig Carnegie Mellon University | ||
12:30 - 14:00 | |||
12:30 90mLunch | Tuesday Lunch ICSE Catering | ||
13:00 - 14:00 | MSR Poster (Tuesday)Mining Challenge / Data and Tool Showcase Track / Technical Papers / Program at Canada Hall 3 Poster Area | ||
13:00 60mTalk | Chasing the Clock: How Fast Are Vulnerabilities Fixed in the Maven Ecosystem? Mining Challenge Md Fazle Rabbi Idaho State University, Arifa Islam Champa Idaho State University, Rajshakhar Paul Wayne State University, Minhaz F. Zibran Idaho State University Pre-print | ||
13:00 60mTalk | MaLAware: Automating the Comprehension of Malicious Software Behaviours using Large Language Models (LLMs) Data and Tool Showcase Track BIKASH SAHA Indian Institute of Technology Kanpur, Nanda Rani Indian Institute of Technology Kanpur, Sandeep K. Shukla Indian Institute of Technology Kanpur Pre-print | ||
13:00 60mTalk | A Dataset of Contributor Activities in the NumFocus Open-Source CommunityData/Tool Track Distinguished Dataset Award Data and Tool Showcase Track Youness Hourri University of Mons, Alexandre Decan University of Mons; F.R.S.-FNRS, Tom Mens University of Mons Pre-print | ||
13:00 60mTalk | Popularity and Innovation in Maven Central Mining Challenge Nkiru Ede Victoria University of Wellington, Jens Dietrich Victoria University of Wellington, Ulrich Zülicke Victoria University of Wellington Pre-print | ||
13:00 60mTalk | TerraDS: A Dataset for Terraform HCL Programs Data and Tool Showcase Track Christoph Buehler University of St. Gallen, David Spielmann University of St. Gallen, Roland Meier armasuisse, Guido Salvaneschi University of St. Gallen Pre-print | ||
13:00 60mTalk | SPRINT: An Assistant for Issue Report Management Data and Tool Showcase Track Pre-print | ||
13:00 60mTalk | Does Functional Package Management Enable Reproducible Builds at Scale? Yes.Technical Track Distinguished Paper Award Technical Papers Julien Malka LTCI, Télécom Paris, Institut Polytechnique de Paris, France, Stefano Zacchiroli LTCI, Télécom Paris, Institut Polytechnique de Paris, Palaiseau, France, Théo Zimmermann Télécom Paris, Polytechnic Institute of Paris Pre-print | ||
13:00 60mTalk | Dependency Update Adoption Patterns in the Maven Software Ecosystem Mining Challenge Baltasar Berretta College of Wooster, Augustus Thomas College of Wooster, Heather Guarnera The College of Wooster | ||
13:00 60mTalk | A Dataset of Software Bill of Materials for Evaluating SBOM Consumption Tools Data and Tool Showcase Track Rio Kishimoto Osaka University, Tetsuya Kanda Notre Dame Seishin University, Yuki Manabe The University of Fukuchiyama, Katsuro Inoue Nanzan University, Shi Qiu Toshiba, Yoshiki Higo Osaka University Pre-print | ||
13:00 60mTalk | Investigating the Understandability of Review Comments on Code Change Requests Technical Papers Md Shamimur Rahman University of Saskatchewan, Zadia Codabux University of Saskatchewan, Chanchal K. Roy University of Saskatchewan | ||
13:00 60mTalk | Refactoring for Dockerfile Quality: A Dive into Developer Practices and Automation Potential Technical Papers Emna Ksontini University of Michigan, Meriem Mastouri University of Michigan, Rania Khalsi University of Michigan - Flint, Wael Kessentini DePaul University | ||
13:00 60mTalk | Combining Large Language Models with Static Analyzers for Code Review Generation Technical Papers Imen Jaoua DIRO, Université de Montréal, Oussama Ben Sghaier DIRO, Université de Montréal, Houari Sahraoui DIRO, Université de Montréal Pre-print | ||
13:00 60mTalk | Cascading Effects: Analyzing Project Failure Impact in the Maven Central Ecosystem Mining Challenge Mina Shehata Belmont University, Saidmakhmud Makhkamjonoov Belmont University, Mahad Syed Belmont University, Esteban Parra Rodriguez Belmont University | ||
13:00 60mTalk | CoMRAT: Commit Message Rationale Analysis Tool Data and Tool Showcase Track Mouna Dhaouadi University of Montreal, Bentley Oakes Polytechnique Montréal, Michalis Famelis Université de Montréal Pre-print Media Attached File Attached | ||
13:00 60mTalk | Can LLMs Replace Manual Annotation of Software Engineering Artifacts?Technical Track Distinguished Paper Award Technical Papers Toufique Ahmed IBM Research, Prem Devanbu University of California at Davis, Christoph Treude Singapore Management University, Michael Pradel University of Stuttgart Pre-print | ||
13:00 60mTalk | Do LLMs Provide Links to Code Similar to what they Generate? A Study with Gemini and Bing CoPilot Technical Papers Daniele Bifolco University of Sannio, Pietro Cassieri University of Salerno, Giuseppe Scanniello University of Salerno, Massimiliano Di Penta University of Sannio, Italy, Fiorella Zampetti University of Sannio, Italy Pre-print | ||
13:00 60mTalk | Mining a Decade of Contributor Dynamics in Ethereum: A Longitudinal StudyFOSS Award Technical Papers Matteo Vaccargiu University of Cagliari, Sabrina Aufiero University College London (UCL), Cheick Ba Queen Mary University of London, Silvia Bartolucci University College London, Richard Clegg Queen Mary University London, Daniel Graziotin University of Hohenheim, Rumyana Neykova Brunel University London, Roberto Tonelli University of Cagliari, Giuseppe Destefanis Brunel University of London Pre-print | ||
13:00 60mTalk | SCRUBD: Smart Contracts Reentrancy and Unhandled Exceptions Vulnerability Dataset Data and Tool Showcase Track Chavhan Sujeet Yashavant Indian Institute of Technology, Kanpur, Mitrajsinh Chavda Indian Institute of Technology Kanpur, India, Saurabh Kumar Indian Institute of Technology Hyderabad, India, Amey Karkare IIT Kanpur, Angshuman Karmakar Indian Institute of Technology Kanpur, India Pre-print | ||
13:00 60mTalk | Out of Sight, Still at Risk: The Lifecycle of Transitive Vulnerabilities in Maven Mining Challenge Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Krzysztof Rykaczewski Nicolaus Copernicus University in Toruń, Poland, Krzysztof Stencel University of Warsaw Pre-print | ||
13:00 60mTalk | HaPy-Bug - Human Annotated Python Bug Resolution Dataset Data and Tool Showcase Track Piotr Przymus Nicolaus Copernicus University in Toruń, Poland, Mikołaj Fejzer Nicolaus Copernicus University in Toruń, Jakub Narębski Nicolaus Copernicus University in Toruń, Radosław Woźniak Nicolaus Copernicus University in Toruń, Łukasz Halada University of Wrocław, Poland, Aleksander Kazecki Nicolaus Copernicus University in Toruń, Mykhailo Molchanov Igor Sikorsky Kyiv Polytechnic Institute, Ukraine, Krzysztof Stencel University of Warsaw Pre-print File Attached | ||
15:30 - 16:00 | |||
15:30 30mBreak | Tuesday Afternoon Break ICSE Catering | ||
16:00 - 17:30 | Plenary: ClosingProgram / Vision and Reflection at 214 Chair(s): Gabriele Bavota Software Institute @ Università della Svizzera Italiana, Jin L.C. Guo McGill University | ||
16:00 30mTalk | Future of AI4SE: From Code Generation to Software Engineering? Vision and Reflection Baishakhi Ray Columbia University | ||
16:30 30mTalk | Reshaping MSR (and SE) empirical evaluations in 2030 Vision and Reflection Massimiliano Di Penta University of Sannio, Italy | ||
17:00 15mDay closing | Closing Session Program Bram Adams Queen's University, Olga Baysal Carleton University, Ayushi Rastogi University of Groningen, The Netherlands | ||
17:15 15mDay closing | MSR 2026 Presentation Program | ||
19:00 - 22:00 | |||
Accepted Papers
Call for Mining Challenge Papers
NEW: Challenge preprint available here
Using package managers is a simple and common method for reusing code through project dependencies. However, these direct dependencies can themselves rely on additional packages, resulting in indirect dependencies. It may then become complex to get a grasp of the whole set of dependencies of a project. Beyond individual projects, a deep understanding of how software ecosystems work and evolve is also a critical prerequisite for achieving sustained success in software development.
This year’s mining challenge focuses on dependencies and dependency ecosystem analysis using the Goblin framework that has been presented at the previous edition of the MSR conference. Goblin is composed of a Neo4J Maven Central dependency graph and a tool called Weaver for on-demand metric weaving into dependency graphs. As a whole, Goblin is a customizable framework for ecosystem and dependency analysis.
Challenge
The analysis of a software ecosystem graph presents numerous research opportunities, allowing for the investigation of various questions in areas such as structural analysis, community detection, dependency optimization, and risk assessment within the Maven Central ecosystem.
The following suggested questions outline potential research inquiries: Questions in groups 1 to 5 can be addressed with the dependency graph database alone, questions in group 6 require the additional use of the Weaver, and questions in group 7 illustrate examples of inquiries that would require an extension of the Weaver.
- Ecosystem evolution
i. What are the patterns in the growth of the Maven Central graph across different time periods?
ii. Do libraries tend to use more dependencies than in the past?
iii. Is the rhythm of library releases higher than in the past, and how has this rhythm evolved over time?
iv. Does the emergence of project management methods (e.g., agile methods) have any impact on the release rhythm of libraries?
v. To what extent does the ecosystem contain unmaintained libraries?
vi. How do projects with unmaintained dependencies cope with the challenges they face? - Clustering
i. Can we deduce different clusters from Maven Central’s comprehensive dependency graph? How do these clusters interact with one another?
ii. Can dependency-based clustering reveal domain-specific groupings, and how well do they align with known categorizations of projects?
iii. How can clustering be used to identify high-risk clusters in the Maven Central ecosystem?
iv. Which artifacts serve as the most crucial dependencies for the ecosystem (i.e., most depended upon)?
v. How do these central nodes affect the overall health and stability of the ecosystem? - Dependency update
i. How often do projects update their dependencies, and what factors influence this frequency (e.g., project size, popularity, type)?
ii. Whenever an artifact releases a new version, how do its dependents react?
iii. How does the removal or failure of certain projects affect the overall network (e.g., log4j Vulnerability)?
iv. How do major versus minor dependency updates differ in frequency and impact?
v. Do projects tend to avoid major updates due to the potential for breaking changes? - Trends
i. How has the adoption of new frameworks (e.g., Spring Boot, Microservices) changed the dependency structures in Maven Central?
ii. What impact do modern dependency management tools (e.g., Dependabot) have on the ecosystem?
iii. How does the adoption of newer Java versions influence dependency graphs?
iv. Does an artifact’s number of dependents correlate with other popularity metrics such as GitHub stars? - Graph theory
i. How do metrics such as degree distribution, clustering coefficient, and average path length characterize the dependency graph?
ii. Is the graph scale-free, small-world, or does it exhibit other known graph structures?
iii. Are certain types of projects more likely to be central (hubs) or peripheral (leaves) in the graph structure?
iv. Is the graph made up of connected components with no relationship between them?
v. How do shortest path lengths between projects vary, and what does this tell us about the overall connectivity of the ecosystem? - Vulnerability
i. How do vulnerabilities propagate through the dependency network, and which projects are most affected?
ii. What proportion of releases have vulnerabilities? What is the proportion of releases directly and transitively impacted?
iii. What is the average time taken to patch a vulnerability in a dependency?
iv. How do users of an artifact react to the discovery of a vulnerability in that artifact? - Licensing and Compliance
i. Are there dominant license types, and how do they influence the usage and distribution of projects?
ii. How does the choice of licenses affect the artifact graph structure?
iii. What percentage of projects have conflicting licenses within their dependency trees?
Description of the Challenge Dataset and Tooling
The Goblin framework (see figure below) is organized around a Neo4J database of the whole Maven Central dependency graph. This database can be created and updated incrementally using Goblin Miner. The database can be queried directly using Cypher (the Neo4j query language) or through the Goblin Weaver tool. More generally, Goblin Weaver comes with an API for the on-demand weaving of user-programmed metrics of interest (added values) into the dependency graph. Several such metrics are already available: CVEs, popularity, freshness and release rhythm. As a whole, Goblin aims to be a customizable framework for working on software dependencies at the ecosystem level.
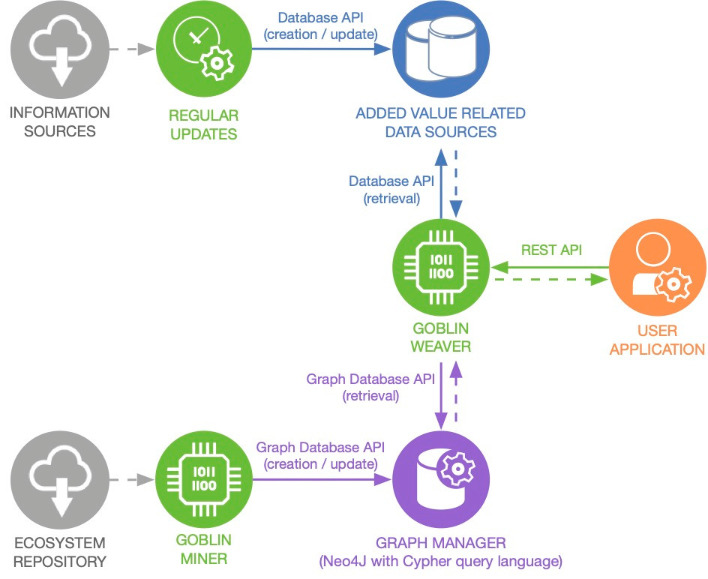
The dependency graph database is composed of two node types (for libraries and for their releases) and two edge types (from releases to their dependencies and from libraries to their releases). The nodes for libraries (type Artifact) contain the Maven id (g.a) information. The nodes for releases (type Release) contain the Maven id (g.a.v), the release timestamp, and the version information. The edges for dependencies (type dependency) are from Release nodes to Artifact nodes and contain target version (which can be a range) and scope (compile, test, etc). The edges for versioning (type relationship_AR) edges are from Artifact nodes to Release nodes.
The latest version of our dataset, dated August 30th, 2024, contains 15,117,217 nodes (658,078 libraries and 14,459,139 releases) and 134,119,545 edges (119,660,406 dependencies and 14,459,139 versioning edges).
We also provide a second version of this dataset enriched with the Weaver metrics, which has the effect of creating new “AddedValue” nodes in the database containing the metrics (CVE (dated September 4, 2024), freshness, popularity and speed).
The Goblin Miner allows you to update the dependency graph database or recreate it from scratch. The Miner Java source code is available.
The Goblin Weaver REST API is available as an alternative for direct access to the database using the Cypher language and for on-demand enrichment of the dependency graph with new information. A memoization principle is available to avoid re-computing enrichments, as soon as the base graph is not re-computed or incremented. For this, new kinds of nodes (type AddedValue) and edges (type addedValues from an Artifact or Release node to an AddedValue node) are used in the graph database. One should be careful, as the graph is large, calculating metrics (especially aggregate ones) for the whole graph can be time-consuming. The Weaver Java source code is available.
A tutorial is available online on this GitHub repository. The issue tracking system will also enable one to ask questions on the datasets and tooling.
How to Participate in the Challenge
First, familiarize yourself with the Goblin framework:
- The Maven Central Neo4j dataset is available on this Zenodo archive.
- To import this dump into Neo4J, please use a dbs version 4.x.
- The Weaver project is available in our GitHub repository.
- This paper https://doi.org/10.1145/3643991.3644879 gives a more in-depth presentation of how the Goblin framework works.
- A project for simply setting up a Neo4j database and Weaver API using Docker is available here: https://github.com/Goblin-Ecosystem/Neo4jWeaverDocker
Use the dataset to answer your research questions, and report your findings in a four-page challenge paper that you submit to our challenge. If your paper is accepted, present your results at MSR 2025 in Ottawa, Canada!
Submission
A challenge paper should describe the results of your work by providing an introduction to the problem you address and why it is worth studying, the version of the dataset you used, the approach and tools you used, your results and their implications, and conclusions. Make sure your report highlights the contributions and the importance of your work. See also our open science policy regarding the publication of software and additional data you used for the challenge.
To ensure clarity and consistency in research submissions:
- When detailing methodologies or presenting findings, authors should specify which snapshot/version of the Goblin dataset (and the Weaver version if used) was utilized.
- Given the continuous updates to the dataset, authors are reminded to be precise in their dataset references. This will help maintain transparency and ensure consistent replication of results.
Submissions must conform to the IEEE formatting instructions IEEE Conference Proceedings Formatting Guidelines (title in 24pt font and full text in 10pt type, LaTeX users must use \documentclass[10pt,conference]{IEEEtran} without including the compsoc or compsocconf options).
Submissions to the Challenge Track can be made via the submission site by the submission deadline. We encourage authors to upload their paper info early (the PDF can be submitted later) to properly enter conflicts for anonymous reviewing. All submissions must adhere to the following requirements:
- Submissions must not exceed the page limit (4 pages plus 1 additional page of references). The page limit is strict, and it will not be possible to purchase additional pages at any point in the process (including after acceptance).
- Submissions must strictly conform to the IEEE conference proceedings formatting instructions specified above. Alterations of spacing, font size, and other changes that deviate from the instructions may result in desk rejection without further review.
- Submissions must not reveal the authors’ identities. The authors must make every effort to honor the double-anonymous review process. In particular, the authors’ names must be omitted from the submission and references to their prior work should be in the third person. Further advice, guidance, and explanation about the double-anonymous review process can be found in the Q&A page from ICSE.
- Submissions should consider the ethical implications of the research conducted within a separate section before the conclusion.
- The official publication date is the date the proceedings are made available in the ACM or IEEE Digital Libraries. This date may be up to two weeks prior to the first day of ICSE 2025. The official publication date affects the deadline for any patent filings related to published work.
- Purchases of additional pages in the proceedings are not allowed.
Any submission that does not comply with these requirements is likely to be desk rejected by the PC Chairs without further review. In addition, by submitting to the MSR Challenge Track, the authors acknowledge that they are aware of and agree to be bound by the following policies:
- The ACM Policy and Procedures on Plagiarism and the IEEE Plagiarism FAQ. In particular, papers submitted to MSR 2025 must not have been published elsewhere and must not be under review or submitted for review elsewhere whilst under consideration for MSR 2025. Contravention of this concurrent submission policy will be deemed a serious breach of scientific ethics, and appropriate action will be taken in all such cases (including immediate rejection and reporting of the incident to ACM/IEEE). To check for double submission and plagiarism issues, the chairs reserve the right to (1) share the list of submissions with the PC Chairs of other conferences with overlapping review periods and (2) use external plagiarism detection software, under contract to the ACM or IEEE, to detect violations of these policies.
- The authorship policy of the ACM and the authorship policy of the IEEE.
Upon notification of acceptance, all authors of accepted papers will be asked to fill a copyright form and will receive further instructions for preparing the camera-ready version of their papers. At least one author of each paper is expected to register and present the paper at the MSR 2025 conference. All accepted contributions will be published in the electronic proceedings of the conference.
This year’s mining challenge and the data can be cited as:
@inproceedings{
title={Navigating and Exploring Software Dependency Graphs using Goblin},
author={Jaime, Damien and El Haddad, Joyce and Poizat, Pascal},
year={2025},
booktitle={Proceedings of the International Conference on Mining Software Repositories (MSR 2025)},
}
A preprint is available online: https://hal.science/hal-04777703
Submission Site
Papers must be submitted through HotCRP: https://msr2025-challenge.hotcrp.com/
Important Dates
AoE: Anywhere on Earth
- Abstract Deadline: Dec 3, 2024 AoE
- Paper Deadline: Dec 6, 2024 AoE
- Author Notification: Jan 12, 2025 AoE
- Camera Ready Deadline: Feb 5, 2025 AoE
Open Science Policy
Openness in science is key to fostering progress via transparency, reproducibility and replicability. Our steering principle is that all research output should be accessible to the public and that empirical studies should be reproducible. In particular, we actively support the adoption of open data and open source principles. To increase reproducibility and replicability, we encourage all contributing authors to disclose:
- the source code of the software they used to retrieve and analyze the data
- the (anonymized and curated) empirical data they retrieved in addition to the Goblin Maven dataset
- a document with instructions for other researchers describing how to reproduce or replicate the results
Already upon submission, authors can privately share their anonymized data and software on archives such as Zenodo or Figshare (tutorial available here). Zenodo accepts up to 50GB per dataset (more upon request). There is no need to use Dropbox or Google Drive. After acceptance, data and software should be made public so that they receive a DOI and become citable. Zenodo and Figshare accounts can easily be linked with GitHub repositories to automatically archive software releases. In the unlikely case that authors need to upload terabytes of data, Archive.org may be used.
We recognise that anonymizing artifacts such as source code is more difficult than preserving anonymity in a paper. We ask authors to take a best effort approach to not reveal their identities. We will also ask reviewers to avoid trying to identify authors by looking at commit histories and other such information that is not easily anonymized. Authors wanting to share GitHub repositories may want to look into using https://anonymous.4open.science/ which is an open source tool that helps you to quickly double-blind your repository.
We encourage authors to self-archive pre- and post prints of their papers in open, preserved repositories such as arXiv.org. This is legal and allowed by all major publishers including ACM and IEEE and it lets anybody in the world reach your paper. Note that you are usually not allowed to self-archive the PDF of the published article (that is, the publisher proof or the Digital Library version). Please note that the success of the open science initiative depends on the willingness (and possibilities) of authors to disclose their data and that all submissions will undergo the same review process independent of whether or not they disclose their analysis code or data. We encourage authors who cannot disclose industrial or otherwise non-public data, for instance due to non-disclosure agreements, to provide an explicit (short) statement in the paper.
Best Mining Challenge Paper Award
As mentioned above, all submissions will undergo the same review process independently of whether or not they disclose their analysis code or data. However, only accepted papers for which code and data are available on preserved archives, as described in the open science policy, will be considered by the program committee for the best mining challenge paper award.
Best Student Presentation Award
Like in the previous years, there will be a public voting during the conference to select the best mining challenge presentation. This award often goes to authors of compelling work who present an engaging story to the audience. Only students can compete for this award.
Call for Mining Challenge Proposals
The International Conference on Mining Software Repositories (MSR) has hosted a mining challenge since 2006. With this challenge, we call upon everyone interested to apply their tools to a common dataset. The challenge is for researchers and practitioners to bravely use their mining tools and approaches on a dare.
One of the secret ingredients behind the success of the International Conference on Mining Software Repositories (MSR) is its annual Mining Challenge, in which MSR participants can showcase their techniques, tools, and creativity on a common data set. In true MSR fashion, this data set is a real data set contributed by researchers in the community, solicited through an open call. There are many benefits of sharing a data set for the MSR Mining Challenge. The selected challenge proposal explaining the data set will appear in the MSR 2025 proceedings, and the challenge papers using the data set will be required to cite the challenge proposal or an existing paper of the researchers about the selected data set. Furthermore, the authors of the data set will join the MSR 2025 organizing committee as Mining Challenge (co-)chair(s), who will manage the reviewing process (e.g., recruiting a Challenge PC, managing submissions, and reviewing assignments). Finally, it is not uncommon for challenge data sets to feature in MSR and other publications well after the edition of the conference in which they appear!
If you would like to submit your data set for consideration for the 2025 MSR Mining Challenge, prepare a short proposal (1-2 pages plus appendices, if needed) containing the following information:
- Title of data set.
- High-level overview:
- Short description, including what types of artifacts the data set contains.
- Summary statistics (how many artifacts of different types).
- Internal structure:
- How are the data structured and organized?
- (Link to) Schema, if applicable
- How to access:
- How can the data set be obtained?
- What are recommended ways to access it? Include examples of specific tools, shell commands, etc, if applicable.
- What skills, infrastructure, and/or credentials would challenge participants need to effectively work with the data set?
- What kinds of research questions do you expect challenge participants could answer?
- A link to a (sub)sample of the data for the organizing committee to pursue (e.g., via GitHub, Zenodo, Figshare).
Submissions must conform to the IEEE conference proceedings template, specified in the IEEE Conference Proceedings Formatting Guidelines (title in 24pt font and full text in 10pt type, LaTeX users must use \documentclass[10pt,conference]{IEEEtran} without including the compsoc or compsocconf options). Submit your proposal here.
The first task of the authors of the selected proposal will be to prepare the Call for Challenge Papers, which outlines the expected content and structure of submissions, as well as the technical details of how to access and analyze the data set. This call will be published on the MSR website on September 2nd. By making the challenge data set available by late summer, we hope that many students will be able to use the challenge data set for their graduate class projects in the Fall semester.
Important dates:
AoE: Anywhere on Earth
- Submission site: https://msr2025.hotcrp.com
- Deadline for proposals: August 19, 2024
- Notification: August 26, 2024
- Call for Challenge Papers Published: September 2, 2024
| Wed 5 Feb 2025 Camera Ready Deadline |
| Sun 12 Jan 2025 Author Notification |
| Fri 6 Dec 2024 Paper Deadline |
| Tue 3 Dec 2024 Abstract Deadline |

Jerin Yasmin
Queen's University, Canada
Canada

Christian Macho
University of Klagenfurt
Austria

Alexandre Decan
University of Mons; F.R.S.-FNRS
Belgium

Benoit Baudry
Université de Montréal
Canada

Mahmoud Alfadel
University of Calgary
Canada

Filipe Cogo
Centre for Software Excellence, Huawei Canada
Canada

Ben Hermann
TU Dortmund
Germany

Damien Jaime
Université Paris Nanterre & LIP6
France

Joyce El Haddad
Université Paris Dauphine - PSL
France

Pascal Poizat
Université Paris Nanterre & LIP6
France

Takashi Ishio
Future University Hakodate
Japan

Dong Wang
Tianjin University
China

Abdoul Kader Kaboré
University of Luxembourg
Luxembourg

Lina Ochoa
Eindhoven University of Technology

Thomas Degueule
Univ. Bordeaux, CNRS, Bordeaux INP, LaBRI, UMR 5800
France

Dhanushka Jayasuriya
University of Auckland
New Zealand

Christoph Treude
Singapore Management University
Singapore

Raula Gaikovina Kula
The University of Osaka
Japan